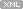
출처 : http://bebop.emstone.com/projects/programming_rules/emstone_guidelines/c_coding_style
Contents
코딩 스타일(Conding Style)이란
소스 코드가 작성되는 형식을 말한다. C를 예로들면 중괄호({})의 위치, 들여쓰기, 괄호가 사용되는 방법들을 의미하는 것이다.
대부분의 오픈 소스 프로젝트에서는 가능하면 프로그래머 개인의 취향이 강하게 반영되는 코딩 스타일에 그리 많은 제약을 하지 않지만, 코드의 '일관성'은 매우 중요하게 여긴다. 즉, 하나의 모듈이나 프로젝트에서는 가능하면 우선적으로 작성된 방식의 코딩 스타일을 따르는 것은 최소한의 예의면서 동시에 프로그램의 일관성을 지키도록 도와 준다.
여기서 기술하는 코딩 스타일은 많이 알고 있는 리눅스 커널 코딩 스타일과 Glib, Gtk+등을 포함하는 GNOME 관련 프로그래밍에서 사용되는 방식을 뼈대로 하지만, 필요한 부분만 발췌하고 나머지는 새로 추가된 것이다.
GNU에서 기본적으로 제안하는 GNU 방식의 코딩 스타일의 특징은 들여쓰기 단위가 2칸, 모든 중괄호는 새로운 행에서 시작한다는 점이다. 그래서 어떤 면에서는 코드 내부의 블럭별 구분이 쉬워지고, Gtk+ 프로그래밍과 같이 API 이름이 대부분 긴 프로그래밍을 할때 웬만해선 하나의 명령어가 한 줄을 넘어가지 않아서 보기 좋다는 장점이 있다. 하지만, 중괄호 위치를 놓는 방식은 실제 코드보다 중괄호에 할당되는 여백이 더 많고, 로직의 깊이에 신경쓰지 않는 프로그래밍 습관을 낳을 우려가 있으며, 결정적으로 이맥스가 아닌 에디터에서는 배보다 배꼽이 더 큰 코딩스타일이 되버린다.
리눅스 커널 코딩 스타일은 위에서 말한 장점과 단점이 그대로 반대가 되는 경우이다. (리눅스 커널 코딩 스타일 문서에 있는 리눅스의 농담을 무시하라. GNU의 코딩 스타일은 개인적인 선호와는 별개로 소프트웨어 공학 관점에서는 코드의 유지보수와 디버깅, 그리고 버그 없는 코드를 만드는데 매우 효율적인 것으로 알려져 있다)
들여쓰기 및 텍스트 너비
들여쓰기는 리눅스 커널 코딩 스타일과 같은 8 칸을 기준으로 하며, 공백문자(space)가 아닌 탭(tab) 문자를 사용하는 것을 원칙으로 한다.
8칸 탭을 사용하면 좋은 가장 큰 이유는 코드 읽기가 쉬워진다는 점이다. 또한 리눅스코딩스타일 에서도 지적한 바와 같이 들여쓰기 깊이가 3단계를 넘어갈 경우 (이런 경우 80칸 기준의 터미널에서는 반드시 행이 넘어가서 코드가 못생겨진다) 함수 설계가 잘못 되었다는 걸 의미한다. 즉, 그런 경우 다른 함수로 모듈화하거나 다른 방법을 검토해 보아야 한다.
소스코드가 씌어지는 텍스트의 너비는 80칸 을 기준으로 한다. 넘어가게 될 경우 다음 줄에 한 단계 더 들여쓰기를 해 이어 작성한다. 하지만 만일 이어지는 코드가 의미적으로 반드시 같은 라인에 있는게 코드의 가독성을 높일 경우 한 라인에 작성해도 된다. 80칸 기준에 너무 얽매이기 보다는 적당한 여유를 두되 전체적으로 일관성을 유지하도록 하는게 좋다.
함수 호출 인수 같은 파라미터는 다음과 같이 괄호 다음 첫번째 인수에 맞춰 정렬한다. 하지만 그리 많지 않다면 한 줄에 모두 넣는 것을 권장한다.
loving_you_with_or_without_me_f(first_param, second_param,
third_parameter, fourth_param);
함수 이름이 너무 길어 인수를 적을 공간이 적을 경우 다음과 같은 형태도 가능하다.
loving_you_with_or_without_me_f(
first_parameter, /* with you ? */
second_parameter, /* without you ? */
third_parameter, /* etc... */
fourth_parameter);
만일 이맥스(Emacs) 사용자라면 리눅스 커널 들여쓰기 스타일을 다음과 같이 ~/.emacs 파일에 저장하면 편하게 사용할 수 있다.
(add-hook 'c-mode-common-hook
(lambda ()
(c-set-style "k&r")
(setq c-basic-offset 8)))
21.x 버전 이후의 ''이맥스''에서는 다음과 같은 설정으로 충분하다.
(add-hook 'c-mode-common-hook
(lambda ()
(c-set-style "linux")))
Vi(m) 을 사용한다면 다음과 같은 설정을 ~/.vimrc 파일에 넣는 것 만으로 충분하다.
set ts=8
if !exists("autocommands_loaded")
let autocommands_loaded = 1
augroup C
autocmd BufRead *.c set cindent
augroup END
endif
하지만 가독성을 위해 한 줄을 여러 줄로 나눌 경우 CVS나 SubVersion 같은 버전관리 시스템을 사용할때 버전별 차이점(diff)을 확인할때는 오히려 가독성이 떨어진다. 예를 들어 의미적으로 한 줄만 변경되었는데 코드 상으로 여러 줄이 변경될 경우 그 차이점을 추적할때 매우 피곤해지는 걸 느낄 수 있다.
indent 프로그램
이맥스 나 Vim 같은 에디터가 아니더라도 좋은 에디터는 대부분 코딩 스타일에 따라 커스터마이징할 수 있는 기능이 있다. 하지만, 그런 기능이 없더라도 코드의 내용은 건드리지 않으면서 코드의 모양만 다시 가공해주는 프로그램이 indent 이다.
매뉴얼을 찾아보면 더 많고 자세한 옵션을 알수 있지만, 대개 -kr 옵션만 주어도 예쁘고 이 문서에 비슷한 코딩 스타일을 얻을 수 있다. 하지만, 조금 더 세밀하게 조정된 옵션은 다음과 같다.
-kr -i8 -ts8 -br -nce -bap -sob -l80 -npcs -ncs -nss -bs -di1 -nbc -lp -npsl
위 내용을 가지는 .indent.pro 라는 이름의 파일을 자신의 홈디렉토리나 실행중인 디렉토리에 넣으면 indent 는 자동으로 옵션을 읽어들이게 된다.
하지만 명심할 것은, indent 가 반드시 나쁜 프로그래밍 습관을 고쳐주지는 않는다는 점이다.
중괄호 위치
들여쓰기와는 달리, 하나의 중괄호 치는 방법을 선택해야 할 이유는 별로 없지만, 여기서 선택한 방법은 C와 C++의 저자들이 즐겨 쓰던 방법인 여는 괄호를 줄 마지막에 놓고, 닫는 괄호는 맨 앞에 놓는 것이다.
if (x is true) {
we do y;
} else {
wo do z;
}
for (i = 0; i < max; i++) {
;
}
switch (prev->state) {
case TASK_INTERRUPTIBLE:
if (unlikely(signal_pending(prev))) {
prev->state = TASK_RUNNING;
break;
}
default:
deactivate_task(prev, rq);
case TASK_RUNNING:
;
}
코드의 라인 수로 프로그래머의 생산량을 판단하던 시절이라면 이런 코딩 스타일은 분명히 환영받지 못할 것이다. 하지만 반대로 이 방법은 중괄호를 넣기 위해 한 줄을 낭비할 필요가 없으며 유용한 주석을 코드에 더 넣을 수 있는 여지를 준다.
하지만 분명히 함수만은 다른 규칙을 따른다. 중괄호를 다음 라인의 시작에 넣는다. 이는 C뿐 아니라, C++과 같은 클래스 내부 함수를 직접 코딩할때도 해당한다.
int function(int x)
{
body of function
}
닫는 괄호에 대한 예외 는 문장에 이어지는 부분이 있을 경우이다. 예를 들어 do ~ while 절과 연속되는 else if 절이다. 이 역시 K&R을 따른 것이다.
do {
body of do-loop
} while (condition);
if (x == y) {
..
} else if (x > y) {
...
} else {
....
}
이름짓기
이름 짓기, 즉 명명법은 코딩 스타일에서 가장 반드시 지켜야 할 만큼 중요하다. 특히 공동 작업으로 이루어지는 개발 프로젝트에서는 함수나 변수의 이름을 통해서 많은 정보를 추가 노력 없이 얻을 수 있기 때문에 코딩은 물론 코드 이해에 드는 노력도 줄어든다.
물론 C++과 달리 C 언어에서는 별다른 이름 공간(Name Space)를 구분하지 않기 때문에 전체적인 이름 공간을 오염시키지 않기 위해서도 반드시 필요하다. 다시 말하면, 서로 다른 모듈에 같은 이름의 함수가 있을 경우 컴파일 후 링크시 이름 충돌로 인해 에러가 발생한다. 또한 규칙 없이 사용된 이름은 코드의 재사용 및 추적을 매우 어렵게 한다.
함수 이름 은 모두 소문자로 이루어지며, 다음과 같은 규칙을 따른다.
{프로젝트}_모듈{_하위모듈}_동사/형용사{_목적어}
구성한다. 여기서 중괄호({})로 둘러 쌓인 부분, 즉 프로젝트 이름과 하위모듈은 경우에 따라 생략될 수 있다는 것을 의미한다. 프로젝트 이름은 약자를 사용할 수도 있고, 프로젝트 이름을 그대로 사용할 수도 있다.
전역 변수 이름 역시 함수와 같은 규칙으로 구성된다. 이는 static 이 붙는 모듈 내부의 전역 변수도 포함된다.
{프로젝트}_모듈{_하위모듈}_명사/형용사
짧은 약어 같은 이름을 사용하면 안된다. 전역변수나 구조체, 클래스에 종속된 변수는 반드시 길고 서술적인 이름을 사용해야 한다. 리누스가 얘기한 것처럼 이름은 설명적이어야 한다. cntusr() 같은 이름 대신 count_active_users() 와 같은 이름을 사용한다. 이는 코드를 더욱 읽기 쉽게 하며 그 자체가 문서 역할을 하게 된다.
하지만, 가능하면 모듈 외부로 전역 변수를 공개하는 것은 피해야 한다. 성능이나 구조적인 이유 때문에 어쩔 수 없는 경우라 하더라도 반드시 데이터에 접근하기 위한 인터페이스 함수를 제공하는 것이 좋다.
지역 변수(local variables) 는 "i"나 "tmp"처럼 짧은 이름을 사용할 수 있다. 이는 물론 모든 전역 변수가 네이밍룰을 완전히 지킨다는 가정하에서만 옳다. 즉, 약어로 표현된 변수는 지역변수임을 알아채고, 같은 블럭의 시작이나 함수의 시작 부분을 검사하면 바로 확인할 수 있기 때문에 가능하다. 이는 휠씬 쓰기 쉽고 이해하기 어렵지 않으며, 오히려 길게 쓰는 건 비생산적이다. 하지만, 그 이름 역시 오해의 여지가 있으면 안된다.
전체적으로 이러한 규칙은 다음과 항목에도 사용된다.
- 함수 이름은 소문자이며, 밑줄(underscore)로 단어를 구분한다. (e_video_set_property(), viewport_switch_next())
- 매크로(macro)와 열거형(enum)은 대문자이며, 역시 밑줄로 단어를 구분한다. (E_VIDEO_GET_DEVICE(), E_VIDEO_NTSC)
- 클래스(class)나 타입(type), 구조체(struct) 이름은 EVideoDevice 와 같이 대소문자를 섞어쓴다. 구조체의 경우 typedef 문으로 정의하여 사용하는 경우 이름 앞에 '_' 문자를 붙여 타입(type)과 구조체(struct)를 구분한다.
- 객체 안에 포함되는 함수(member functions)도 위의 함수와 같은 규칙을 따른다. 단 유의할 점은, 이름을 지을때 의미 중복을 피해야 한다는 점이다. 이는 아래에서 다시 논한다.
파일 이름 은 약간 다른 규칙을 따른다.
- 대문자 없이 밑줄로 단어를 구분하는 이름을 사용한다.
- 파일 이름은 동일한 이름의 모듈, 구조체, 클래스 이름을 따른다. 즉, 누군가 avmania_ 로 시작하는 함수나 변수를 참고하고 싶을 경우, avmania.h``나 ``avmania.c, avmania.cpp 파일을 열면 바로 찾아볼 수 있도록 해야 한다.
- 파일이 라이브러리의 일부일 경우 라이브러리 이름을 접두어로 항상 붙인다. (예: libpantilt 라이브러리의 파일은 pantilt_ 로 시작)
단어 구분에 밑줄(_)을 사용하면 좋은 점은 코드에 사용할 수 있는 단어를 좀 더 자유롭게 사용할 수 있고, 단위 이동을 지원하는 대부분의 에디터에서 더 쉽고 빠르게 이동하고 편집할 수 있다는 점이다.
일관된 이름
변수 이름을 일관적으로 지어야 한다는 사실은 매우 중요하다. 한 예로, 리스트를 다루는 모듈이 리스트 포인터 변수의 이름을 "l"이라고 지었다. 물론 이는 간결함과 간편함을 위해서다. 하지만, 위젯과 크기를 다루는 모듈이 위젯(widgets)과 가로(widths)를 모두 "w"라고 이름을 지으면 안된다. 이는 코드를 매우 읽기 어렵게 하고 코드의 일관성을 떨어뜨린다.
좋은 변수나 함수 이름을 지을때 일반적 의미의 단어를 피하는 것도 좋은 방법이다. 또한 이름을 지을때 가능한 기술적인 용어를 피하는 것도 좋은 방법이다.
의미 중복 피하기
대부분의 경우 하나의 이름에는 같은 단어가 두 개 이상 들어갈 필요가 없다. 또한 단어가 중복되면 타이핑에 드는 노력도 더 많이 든다. 반드시 의미상으로 구분해야할 필요가 있을 경우에만 같은 단어를 사용하는 것을 원칙으로 한다.
특히 구조체나 클래스의 함수 이름 같은 경우 구조체나 클래스의 이름이 이미 포함하고 있는 내용을 함수 이름에 다시 넣는 경우가 많은데, 이는 피해야 한다.
함수
함수는 짧고 예뻐야 하며 단지 한가지 일만 해야 한다. 특히 switch ~ case``문이 아닌 ``if ~ else if 가 길게 반복되는 코드에서 각 블럭이 길어질 경우 하나의 함수로 분리하는 것을 고려한다. 성능을 고려해야 된다면 static inline 을 함수 앞에 붙이는 것과 같은 컴파일러의 인라인(in-line) 기능을 이용하면 된다. 컴파일러는 프로그래머가 원하는 코드를 생성해 줄 것이다.
특히 복잡한 함수일 경우, 영어를 할 줄 아는 고등학교 1학년 학생이 읽어도 코드를 이해할 수 있을만큼의 코드를 작성하기는 힘들다. 이를 위해서는 실행 단위별로 주석을 다는 방법도 괜찮지만, 각각의 실행 단위를 충분히 설명적인 보조 함수로 나누는 것도 좋은 방법이다.
또 하나의 고려사항은 함수에서 사용하는 지역변수의 개수이다. 지역변수는 5~10개를 넘지 말아야 한다. 만일 그렇다면 뭔가 잘못하고 있는 것이다. 다시 생각해보고, 더 작은 단위로 나눈다. 일반적으로 사람의 두뇌는 서로 다른 7가지 일은 동시에 유지할 수 있지만, 그 이상이 되면 힘들어지는 것으로 알려져 있다. 당신이 천재라 할 지라도, 2주 전에 자신이 작성한 코드를 이해하고 싶을 때가 올 것이다.
static과 const 사용
들여쓰기와 이름의 일관성만 지켜도 코드는 거의 명료해진다. 하지만 이 두가지는 프로그래머, 즉 사람의 뇌를 피곤하지 않게 하기 위한 방법일 뿐이다. 하지만, 컴파일러의 도움을 받으면 프로그래머는 더욱 즐거워진다.
모든 함수와 변수는 항상 static 으로 선언한다. 그리고 현재 모듈 바깥에서 사용하는 것만 진짜 전역(global) 함수로 선언한다.
이 방법의 장점은 첫째 static 키워드가 붙은 키워드는 모듈 밖에서 참조할 수 없도록 컴파일러가 막아주기 때문에, 다시 말해 전역으로 취급되지 않기 때문에(export) 전체적인 소프트웨어 코드의 이름 공간(name space)을 오염시키지 않는다. 두번째 장점은 이름 공간이 현재 모듈로만 제한되기 때문에 다른 모듈에서 내부에서 사용할지 모르는 어떤 이름이라도 마음 놓고 사용할 수 있다. 따라서 모듈 안에서만 사용되는 간단한 함수에 이름짓기 규칙을 반영할 필요가 없어져 두뇌 노동을 덜 수 있다. 그리고, 마지막으로 GCC와 같은 컴파일러는 -Wall -Wunused 옵션을 주어 컴파일하면 static 으로 선언이 되었으면서도 한 번도 사용된 적이 없으면 경고해 준다. 따라서 복잡한 로직에서 빠뜨리기 쉬운 점을 다시 한 번 검토할 수 있다.
const 키워드 역시 남용해 주길 바란다. 이를 통해 컴파일러는 더욱 많은 숨겨진 버그를 찾아줄 것이다.
사용자가 해제(free)하면 안되는 내부 데이터 포인터를 돌려주는 함수가 있다면, const 를 사용해야 한다. 이는 사용자가 그런 작업을 하려 하면 자동으로 경고해 줄 것이다. 다음 예제에서 컴파일러는 함수가 돌려준 문자열을 해제하는 코드가 있을 경우 사용자에게 경고할 것이다.
const char *man_get_name_by_id(int id);
매크로 및 enum
규칙이 없는 마법수(magic values) 는 코드에 숫자 그대로 적지 말고 항상 매크로를 사용해 정의한다.
/* Amount of padding for GUI elements */ #define GNOME_PAD 8 #define GNOME_PAD_SMALL 4 #define GNOME_PAD_BIG 12
한 변수에 가능한 값이 여러개일 경우 대부분의 경우 매크로를 이용해 그 값을 정의해 사용한다. 하지만 그렇게 하지 말라. 반드시 enum 을 사용해 정의하라. 컴파일러는 물론 디버거까지도 그 값에 대한 심볼 정보를 알게 되기 때문에 컴파일시 뿐 아니라 디버깅 시에도 암호 같은 숫자 대신 enum 으로 정의한 심볼을 볼 수 있을 것이다. 물론 이런식으로 선언된 열거형 변수를 int형 으로 선언하지 말고 반드시 enum 에서 정의한 타입으로 선언해야 효과가 있다. 다음 예제는 매우 많이 처하는 환경의 한 예일 것이다.
/** Shadow types */
typedef enum {
GTK_SHADOW_NONE,
GTK_SHADOW_IN,
GTK_SHADOW_OUT,
GTK_SHADOW_ETCHED_IN,
GTK_SHADOW_ETCHED_OUT
} GtkShadowType;
void gtk_frame_set_shadow_type (Gtkframe *frame, GtkShadowType type);
이런 방법은 비트 필드(bit field)방식의 집합에도 적용할 수 있다.
/** Update flags for items */
typedef enum {
GNOME_CANVAS_UPDATE_REQUESTED = 1 << 0,
GNOME_CANVAS_UPDATE_AffINE = 1 << 1,
GNOME_CANVAS_UPDATE_CLIP = 1 << 2,
GNOME_CANVAS_UPDATE_VISIBILITY = 1 << 3,
GNOME_CANVAS_UPDATE_IS_VISIBLE = 1 << 4
} GnomeCanvasUpdateType;
헤더 파일
한 모듈의 헤더 파일은 그 모듈의 인터페이스 역할을 한다. 즉, 외부에서 모듈에 접근하기 위한 API와 그 API를 사용하는데 필요한 자료구조나 정의만 포함해야 한다.
모듈 안에서 헤더 파일을 포함(include)할때는 다음과 같은 순서로 정렬한다.
- 시스템 라이브러리 헤더 파일
- 다른 모듈 헤더 파일
- 자신의 인터페이스 헤더 파일
좋은 코딩 습관
위에서 적은 코딩 스타일 외에 다음 내용은 머리와 손이 습관처럼 따라야할 프로그래밍 습관이다.
- 특별한 예외가 아닌 이상 파일 이름도 위의 이름 규칙을 따른다.
- 파일 이름과 모듈 이름은 가능하면 일치시켜라. 예를 들어 e_video_* 형태의 API는 e_video.c 파일에 위치하는 것이 좋다.
- 헤더파일에는 그 모듈의 인터페이스만 두어라. 반드시 extern 을 앞에 붙이고, 다른 모듈에서 사용할 수 있는 그 모듈의 API만 두어라. 선언이나 형도 API를 사용하는데 필요한 것만 헤더파일에 둔다.
- 절대로 애매한 코드는 작성하지 말고, 항상 엄격하게 작성하라.
- 수식을 명확하게 표현하는 것 이상의 괄호를 사용하지 말라.
- 모든 키워드의 앞뒤, 콤마(,) 다음, 이진연산자(+, -, ...) 앞뒤에 공백을 넣어라.
- 어설프게 코드를 수정하려 하지 말고, 명료하고 확장가능하며 유지보수가 쉬운 코드를 다시 만들어라.
- 컴파일시 단 하나의 경고(warnings) 메시지도 무시하지 말고, 먼저 처리해서 없애라. 이는 헤더파일에 있는 함수 프로토타입 일치성 등과 같은 흘리기 쉬운 버그들을 잡도록 도와 준다.
- 주석을 달아라. 각 함수 앞부분에 무엇을 하는 녀석인지 설명해 두는 것을 잊지 말라. 절대로 필요한 경우가 아니면, 어떻게(HOW) 동작하는지는 적지 말고 무엇을(WHAT) 하는지 기술하라. 그런 건 코드를 읽어보면 안다. 그렇지 않다면, 코드를 이해하기 쉽도록 다시 작성하라. 하지만, 라이브러리나 운영체제, 환경 상의 이유로 일부러 그렇게 작성한 코드는 반드시 주석을 달아야 한다.
'개발 노트' 카테고리의 다른 글
| General Purpose Hash Function for C, C++ (0) | 2008.06.11 |
|---|---|
| 설치형 블로그 Text Cube 설치 하기 (0) | 2008.06.10 |
| 윈도우 터미널 서비스 포트 변경 (0) | 2008.04.23 |
| 특정 문자를 제거하는 함수를 구현하라. (0) | 2008.03.30 |
| UltraEdit로 Ruby 개발하기! (Highlight) (0) | 2008.03.27 |

 invalid-file
invalid-file invalid-file
invalid-file
 invalid-file
invalid-file

