Aspect Oriented Programming (AOP) in Spring Framework
작성자 : 김문규
최초 작성일 : 2008. 7.10
1. 정의
AOP는 Spring Framework의 중요한 특징 중 하나입니다.
AOP란, 기능을 핵심 비지니스 로직과과 공통 모듈로 구분하고, 핵심 로직에 영향을 미치지 않고 사이사이에 공통 모듈을 효과적으로 잘 끼워넣도록 하는 개발 방법입니다.
공통 모듈은 보안 인증, 로깅 같은 요소들이 해당됩니다.
예를 들어 다시 설명하면, 로그를 찍기위해 로그 출력 모듈을 만들어서 직접 코드 사이사이에 집어 넣을 수 있겠지요? 이런건 AOP 적이지 않은 개발입니다.
반면에 로그 출력 모듈을 만든 후에 코드 밖에서 이 모듈을 비지니스 로직에 삽입하는 것이 바로 AOP 적인 개발입니다. 코드 밖에서 설정된다는 것이 핵심입니다.
2. 예제
1) AOP스럽지 못한 코드
2) Spring에서 AOP를 사용하는 방법
Spring에서는 크게
- Spring API를 이용하는 방법
- XML schema을 이용하는 방법
- Annotation 기능을 이용한 방법
이 있습니다.
여기서는 2번째 XML schema를 이용하는 방법의 예제를 소개합니다.
전체 소스를 첨부합니다.
먼저 AOP 관련 용어를 설명하도록 하겠습니다.
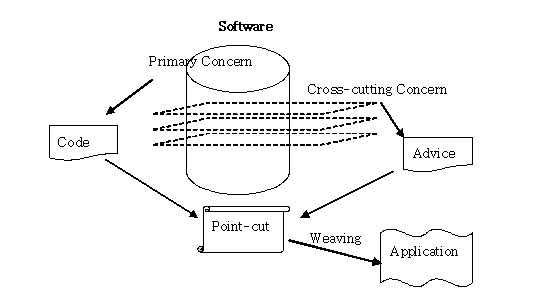
- advice : 여러 객체에 공통으로 적용되는 공통 관심 사항
- joinpoint : 공통 기능 적용 가능 지점 (spring에서는 메서드 호출만이 가능합니다.)
- pointcut : joinpoint 중에 실제로 적용할 지점
- weaving : 핵심 로직에 공통 로직을 삽입하는 것
- aspect : 언제 어떤 기능을 적용할 지에 대한 정의
설정 정보는 아래의 구조로 생성합니다.
<aop:config>
<aop:aspect> : aspect를 설정
<aop:before> : method 실행 전
<aop:after-returning> : method 정상 실행 후
<aop:after-throwing> : method 예외 발생 시
<aop:after> : method 실행 후 (예외 발생 예부 상관 없음)
<aop:around> : 모든 시점 적용 가능
<aop:pointcut> : pointcut 설정
pointcut 설정은 AspectJ의 표현식에 따릅니다.
이제 모든 설정은 끝났습니다. 그닥 힘들이지 않고 설정할 수 있습니다. 하지만 joinpoint에 해당되는 지점만 적용이 가능하기 때문에 사용해야 할 시점을 잘 선택해야 할 듯 합니다.
3. 맺음말
지금까지 필터같은 기술을 이용해서 이와 비슷한 기능을 구현 했었지요. 실제 대형 과제를 할 경우에는 더욱더 필요한 기능이 아닌가 싶습니다. 아무리 모듈화를 하고 그 모듈을 적용한다 하더라도 일일이 코드에 적용하는 것은 정말 귀찮은 일일뿐 아니라 오류의 소지도 많아지게 됩니다. 그렇기 때문에 AOP는 정말 유용한 기능이 아닐 수 없습니다. 개인적인 생각으로는 이거 하나만으로도 spring을 써야할 이유가 아닐까 합니다. 제가 드린 예제를 기반으로 꼭 여러분의 과제에 적용해 보시길 바랍니다. 감사합니다.
4. 참조
마지막으로 AOP를 이해하는 것에 많은 도움을 준 칼럼을 소개하고자 합니다. 한빛미디어에 김대곤님이 기고하신 글입니다.
작성자 : 김문규
최초 작성일 : 2008. 7.10
1. 정의
AOP는 Spring Framework의 중요한 특징 중 하나입니다.
AOP란, 기능을 핵심 비지니스 로직과과 공통 모듈로 구분하고, 핵심 로직에 영향을 미치지 않고 사이사이에 공통 모듈을 효과적으로 잘 끼워넣도록 하는 개발 방법입니다.
공통 모듈은 보안 인증, 로깅 같은 요소들이 해당됩니다.
예를 들어 다시 설명하면, 로그를 찍기위해 로그 출력 모듈을 만들어서 직접 코드 사이사이에 집어 넣을 수 있겠지요? 이런건 AOP 적이지 않은 개발입니다.
반면에 로그 출력 모듈을 만든 후에 코드 밖에서 이 모듈을 비지니스 로직에 삽입하는 것이 바로 AOP 적인 개발입니다. 코드 밖에서 설정된다는 것이 핵심입니다.
2. 예제
1) AOP스럽지 못한 코드
public class InventoryController implements Controller {
protected final Log logger = LogFactory.getLog(getClass());
private ProductManager productManager;
public ModelAndView handleRequest(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
throws ServletException, IOException {
String now = (new java.util.Date()).toString();
logger.info("returning hello view with " + now);
logger.info("returning hello view with " + now);
Map<String, Object> myModel = new HashMap<String, Object>();
myModel.put("now", now);
myModel.put("products", this.productManager.getProducts());
myModel.put("now", now);
myModel.put("products", this.productManager.getProducts());
return new ModelAndView("hello", "model", myModel);
}
}
public void setProductManager(ProductManager productManager) {
this.productManager = productManager;
}
}
로그를 찍고 싶은 지점에 로깅 코드를 직접 삽입하는 방법입니다. 물론 이렇게 하는 것이 효율적일 수도 있습니다. 하지만, 클래스 진입 시점마다 로그를 찍는 것과 같이 동일한 패턴이 있는 경우에는 rule을 정의하고 여기에 따라서 동일한 모듈이 호출된다고 하면 매우 직관적이고 간결하면서 유지 보수가 편하게 구현이 될것으로 생각됩니다. 이것을 지원하는 것이 바로 AOP이며 spring에서는 이를 지원하고 있습니다.this.productManager = productManager;
}
}
2) Spring에서 AOP를 사용하는 방법
Spring에서는 크게
- Spring API를 이용하는 방법
- XML schema을 이용하는 방법
- Annotation 기능을 이용한 방법
이 있습니다.
여기서는 2번째 XML schema를 이용하는 방법의 예제를 소개합니다.
전체 소스를 첨부합니다.
 springapp - aop.zip
springapp - aop.ziploggingaspect.java
package springapp.common;
package springapp.common;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.aspectj.lang.JoinPoint;
import org.apache.commons.logging.LogFactory;
import org.aspectj.lang.JoinPoint;
public class LoggingAspect {
protected final Log logger = LogFactory.getLog(getClass());
// pointcut method 호출 전에 실행 시킬 로깅 함수
public String beforeLogging(JoinPoint joinPoint) {
String methodName = joinPoint.getSignature().getName();
logger.info("calling: " + methodName);
return methodName;
}
// pointcut method 결과 리턴 후에 실행 시킬 로깅 함수
public void returningLogging(JoinPoint joinPoint, Object ret) {
String methodName = joinPoint.getSignature().getName();
logger.info("called successfully: " + methodName + " returns " + ret);
}
// pointcut method에서 예외 발생시에 실행 시킬 로깅 함수
public void throwingLogging(JoinPoint joinPoint, Throwable ex) {
String methodName = joinPoint.getSignature().getName();
logger.info("exception occured: " + methodName + " throws "
+ ex.getClass().getName());
}
// pointcut method 종료 후에 실행 시킬 로깅 함수
public void afterLogging(JoinPoint joinPoint) {
String methodName = joinPoint.getSignature().getName();
logger.info("finish call: " + methodName);
}
}
public String beforeLogging(JoinPoint joinPoint) {
String methodName = joinPoint.getSignature().getName();
logger.info("calling: " + methodName);
return methodName;
}
// pointcut method 결과 리턴 후에 실행 시킬 로깅 함수
public void returningLogging(JoinPoint joinPoint, Object ret) {
String methodName = joinPoint.getSignature().getName();
logger.info("called successfully: " + methodName + " returns " + ret);
}
// pointcut method에서 예외 발생시에 실행 시킬 로깅 함수
public void throwingLogging(JoinPoint joinPoint, Throwable ex) {
String methodName = joinPoint.getSignature().getName();
logger.info("exception occured: " + methodName + " throws "
+ ex.getClass().getName());
}
// pointcut method 종료 후에 실행 시킬 로깅 함수
public void afterLogging(JoinPoint joinPoint) {
String methodName = joinPoint.getSignature().getName();
logger.info("finish call: " + methodName);
}
}
applicationContext.xml
.... (다른 설정 생략)
<bean id="logging" class="springapp.common.LoggingAspect" />
<aop:config>
<aop:pointcut id="publicMethod" expression="execution(public * springapp.service..*.*(..))" />
<aop:aspect id="loggingAspect" ref="logging">
<aop:before pointcut-ref="publicMethod" method="beforeLogging" />
<aop:after-returning pointcut-ref="publicMethod" method="returningLogging" returning="ret" />
<aop:after-throwing pointcut-ref="publicMethod" method="throwingLogging" throwing="ex" />
<aop:after pointcut-ref="publicMethod" method="afterLogging" />
</aop:aspect>
</aop:config>
.... (다른 설정 생략)
.... (다른 설정 생략)
<bean id="logging" class="springapp.common.LoggingAspect" />
<aop:config>
<aop:pointcut id="publicMethod" expression="execution(public * springapp.service..*.*(..))" />
<aop:aspect id="loggingAspect" ref="logging">
<aop:before pointcut-ref="publicMethod" method="beforeLogging" />
<aop:after-returning pointcut-ref="publicMethod" method="returningLogging" returning="ret" />
<aop:after-throwing pointcut-ref="publicMethod" method="throwingLogging" throwing="ex" />
<aop:after pointcut-ref="publicMethod" method="afterLogging" />
</aop:aspect>
</aop:config>
.... (다른 설정 생략)
먼저 AOP 관련 용어를 설명하도록 하겠습니다.
- advice : 여러 객체에 공통으로 적용되는 공통 관심 사항
- joinpoint : 공통 기능 적용 가능 지점 (spring에서는 메서드 호출만이 가능합니다.)
- pointcut : joinpoint 중에 실제로 적용할 지점
- weaving : 핵심 로직에 공통 로직을 삽입하는 것
- aspect : 언제 어떤 기능을 적용할 지에 대한 정의
설정 정보는 아래의 구조로 생성합니다.
<aop:config>
<aop:aspect> : aspect를 설정
<aop:before> : method 실행 전
<aop:after-returning> : method 정상 실행 후
<aop:after-throwing> : method 예외 발생 시
<aop:after> : method 실행 후 (예외 발생 예부 상관 없음)
<aop:around> : 모든 시점 적용 가능
<aop:pointcut> : pointcut 설정
pointcut 설정은 AspectJ의 표현식에 따릅니다.
execution( 수식어패턴 리턴타입패턴 패키지패턴.메소드이름패턴(파라미터패턴) )
이제 모든 설정은 끝났습니다. 그닥 힘들이지 않고 설정할 수 있습니다. 하지만 joinpoint에 해당되는 지점만 적용이 가능하기 때문에 사용해야 할 시점을 잘 선택해야 할 듯 합니다.
3. 맺음말
지금까지 필터같은 기술을 이용해서 이와 비슷한 기능을 구현 했었지요. 실제 대형 과제를 할 경우에는 더욱더 필요한 기능이 아닌가 싶습니다. 아무리 모듈화를 하고 그 모듈을 적용한다 하더라도 일일이 코드에 적용하는 것은 정말 귀찮은 일일뿐 아니라 오류의 소지도 많아지게 됩니다. 그렇기 때문에 AOP는 정말 유용한 기능이 아닐 수 없습니다. 개인적인 생각으로는 이거 하나만으로도 spring을 써야할 이유가 아닐까 합니다. 제가 드린 예제를 기반으로 꼭 여러분의 과제에 적용해 보시길 바랍니다. 감사합니다.
4. 참조
마지막으로 AOP를 이해하는 것에 많은 도움을 준 칼럼을 소개하고자 합니다. 한빛미디어에 김대곤님이 기고하신 글입니다.
'개발 노트' 카테고리의 다른 글
| Function Pointer란? (0) | 2008.07.14 |
|---|---|
| Javascript Object Oriented Programming (1) | 2008.07.14 |
| [Spring Framework ②] Inversion of Control (2) | 2008.07.10 |
| CPPTooltip 사용 예제 (0) | 2008.07.01 |
| X11에서 Pointer를 이동하는 예제 (0) | 2008.07.01 |
 invalid-file
invalid-file